
The Dildo Depreciation: Technical Overview provides a more comprehensive and detailed outline of how I developed and leveraged the solution outlined in my post, '📝The Ultimate Retribution: Divorcing a Dildo with AI'.
Engineer a defensible, AI-powered property assessment system capable of:
- Efficiently cataloguing household items via real-time video analysis.
- Effectively associate visually identified inventory with existing purchase data.
- Accurately assigning 📝Fair Market Value (FMV) assessments across a wide range of household items.
Workflow
- Inventory of Property
- Enrichment of Data
- Processing of Data
- Export of Data
1. Inventory of Property
The inventory process began with the objective of creating a complete, disclosure-ready catalog of household property aligned to the California Judicial Council’s Form FL-160 (📝Property Disclosure). This form’s columns provided the baseline schema—item or item batch name, purchase date, purchase price, gross fair market value, and current fair market value—but the working dataset was extended with additional fields: acquisition source, quantity, condition notes, and ownership notes. These additions were essential for downstream 📝Fair Market Value (FMV) calculations and for clarifying property division (e.g., distinguishing between individual, shared, or company-owned assets).
The capture method relied on 📝Gemini Live, a feature that streams a device’s camera feed to 📝Google's 📝Artificial Intelligence (AI) model capable of simultaneous visual recognition and metadata transcription. However, I also used my 📝Limitless pendant to capture the audio transcript as a backup. The physical process began with preparing the home environment to optimize object detection: ensuring all areas were accessible, lighting was sufficient, and high-density storage was prepped for quick scanning. During the ~1-hour walkthrough, the phone’s camera was moved deliberately to frame each item or batch clearly. Visual capture was paired with narrated details: name or batch name, estimated or exact purchase date, purchase price, acquisition source, item condition with relevant notes, ownership status, and quantity. The AI processed both the video and audio in real time, mapping this information directly to the defined schema.
Upon completing the walkthrough, I asked 📝Gemini to output a 📝Comma-Separated Values (CSV) file matching the disclosure form’s structure. This CSV represented the master inventory—comprehensive in coverage and ready to merge with purchase data. Accuracy and completeness at this stage were critical, as errors in narration or recognition could cascade into downstream enrichment and valuation steps.
2. Enrichment of Data
With the raw inventory in place, the next step was to attach verified purchase metadata to each item, ensuring that the valuation process had transactional accuracy. Two primary data sources were used: 📝Amazon purchase history and email receipts for non-Amazon purchase receipts.
Amazon purchases were extracted using the 📝Amazon Order History Reporter Chrome extension, which allowed for the export of twelve years of order data into CSV format—a necessity after Amazon removed native export capabilities. This CSV included item names, order dates, and purchase prices, and became the foundational dataset for automated matching against the Gemini inventory.
For non-Amazon purchases, a custom 📝Make automation pipeline was deployed. This began with a 📝mailhook module configured to receive forwarded receipt emails. The raw 📝HyperText Markup Language (HTML) from each email was then processed by a Gemini 2.5 Flash module, using a prompt engineered to extract structured 📝JSON from unstructured HTML. The output format was strictly defined: each JSON array contained purchase objects with item_name, purchase_date (ISO 8601), purchase_price, vendor_name, and vendor_website. Multi-item transactions were grouped under a single purchase object to maintain transactional coherence. No speculative data was added; if a field was absent in the source, it was returned as null.
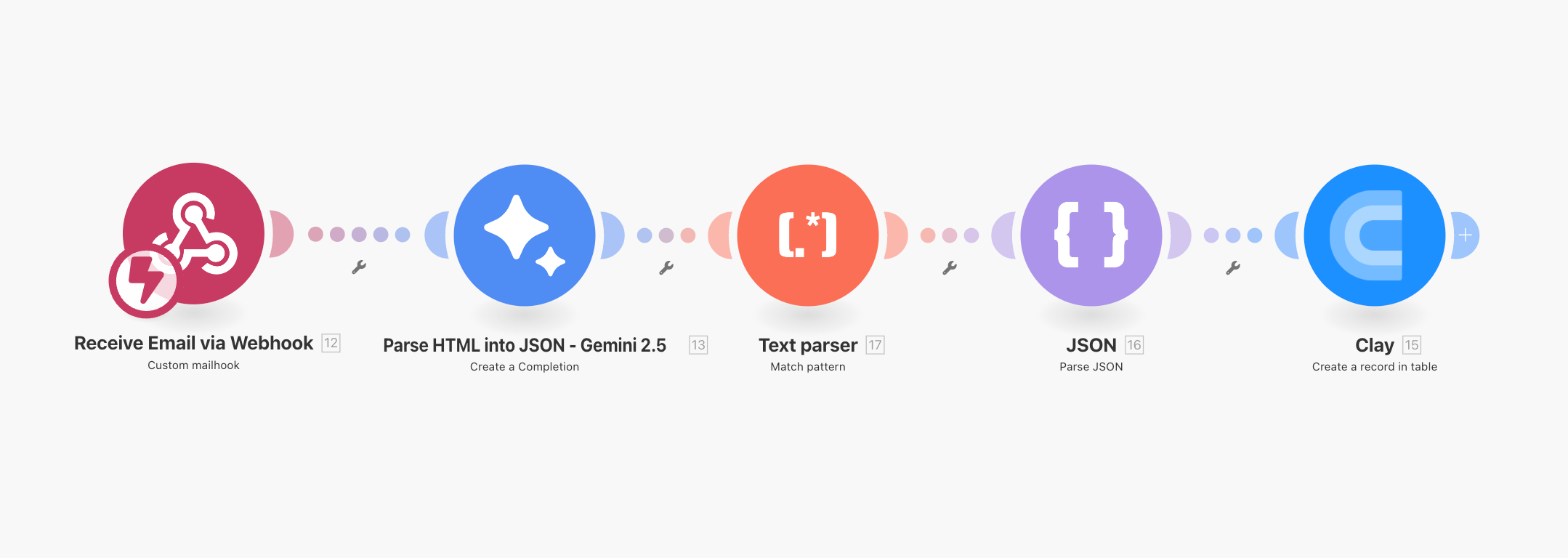
A regex cleaning step removed any unintended formatting, and a final parse step enforced strict adherence to the JSON schema before pushing the data into Clay via a webhook connection.
📝Clay served as the central enrichment platform. Both the Amazon CSV and the Make-derived purchase records were imported into tables designed for integration with the inventory file. Matching was performed through a “Lookup Single Row in Other Table” enrichment: the inventory’s item name was compared against Amazon descriptions using a Contains operator. Automated matching successfully linked the majority of items, but some edge cases required manual review—particularly where item names were generic, abbreviated, or significantly altered in the Amazon record. This hybrid approach balanced automation efficiency with accuracy, avoiding over-engineering in line with the XKCD “time to automate” principle.
3. Processing of Data
The processing stage transformed the enriched dataset into one that could produce consistent and defensible 📝Fair Market Value (FMV) for each item. This required precise prompt engineering to standardize how the AI assigned values across widely varied items—from high-demand electronics to personal items with limited resale markets.
The valuation methodology began with research in Perplexity AI to define criteria suitable for divorce property disclosures under U.S. family law norms. The FMV for each item would be based on recent U.S. sales data from platforms like eBay, with a preference for transactions within the past 90 days and an extension to 180 days if needed. Median sale price was selected as the valuation metric to mitigate the effect of outliers, and all speculative adjustments—such as for inflation or rarity premiums—were prohibited. In the absence of comparable sales data, the fallback was to assign the lowest plausible value, often in the $0–$2 range for unsellable or low-demand items.
These rules were passed into Prime Prompter, a custom GPT-based agent designed to refine prompt language for maximum consistency in LLM outputs. The final system prompt instructed the AI to act as a property valuation specialist, outputting only a JSON object with two keys: FMV (numeric, no formatting) and FMV_rationale (a single paragraph explaining the pricing logic). The model was explicitly barred from using original purchase price unless supported by actual resale data, and from applying any compounding or speculative logic.
Within Clay, this prompt was embedded into a Gemini enrichment. For each inventory record, the model received structured input—item name, original cost, purchase date, condition, and any condition notes—and returned the FMV and rationale. Because the prompt was standardized, the valuations were repeatable: identical inputs consistently produced identical outputs, a key requirement for defensibility in a legal context.
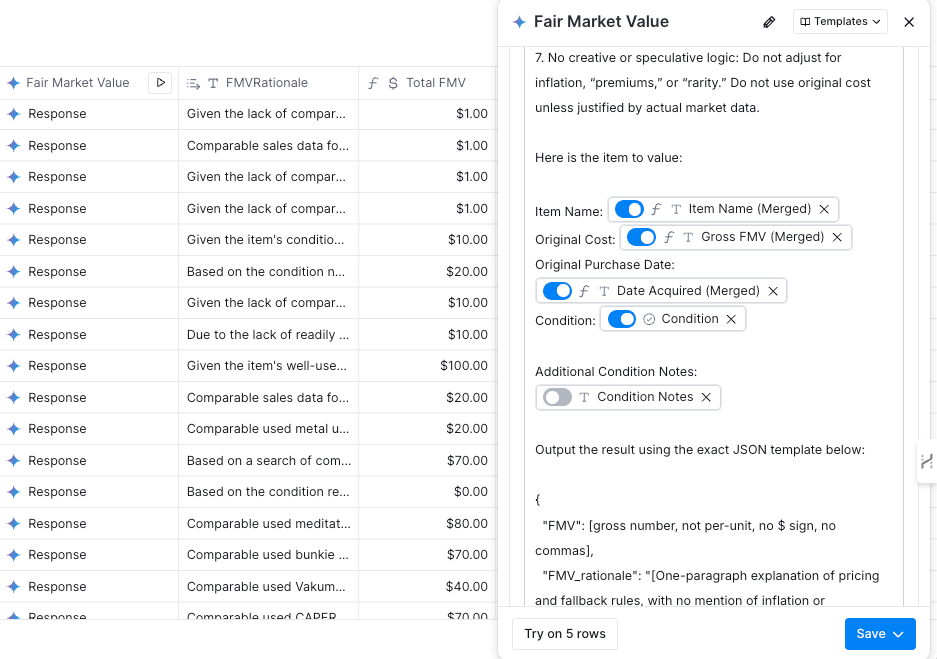
The output from this step augmented the inventory records with two new fields: Gross FMV and FMV Rationale. The former became the value for property disclosure; the latter served as an audit trail to justify the number in court if needed. The structured JSON outputs also simplified potential export to other formats or systems without additional parsing overhead.
4. Export of Data
The final stage was to consolidate the fully processed and valued dataset into a deliverable format suitable for legal submission, internal review, or future reuse in related contexts such as insurance claims. Because the working dataset lived in Clay, exports could be generated in multiple formats—most commonly as a CSV or Airtable-like table for compatibility with legal document preparation workflows.
The exported file contained all schema columns from the initial Gemini Live inventory, enriched with purchase details from Amazon and Make, and appended with FMV data from the processing stage. The result was a single, authoritative table that included for each item: name or batch name, purchase date, purchase price, acquisition source, quantity, condition notes, ownership notes, gross FMV, and FMV rationale.
Beyond the legal requirements, the export’s structure allowed for analytical use. For example, filtering by ownership notes could quickly isolate contested items, while sorting by acquisition source made it easy to cross-verify Amazon matches or identify items lacking purchase metadata. The FMV rationale fields provided immediate traceability to the market logic behind each valuation, supporting both transparency and dispute resolution.
In practice, this system produced not just a one-time divorce disclosure but a reusable framework. The modular design—Gemini Live for capture, Make for parsing receipts, Clay for enrichment and valuation—means the same workflow could be adapted to other high-stakes asset documentation scenarios without substantial modification. By maintaining strict schema discipline, documented prompt rules, and transparent enrichment logic, the process created a dataset that was both technically robust and legally defensible.